Regularized Stacked Autoencoder with Dropout-Layer to Overcome Overfitting in Numerical High-Dimensional Sparse Data
DOI:
https://doi.org/10.37934/ard.129.1.6074Keywords:
sparse data, deep learning, regularized stacked autoencoderAbstract
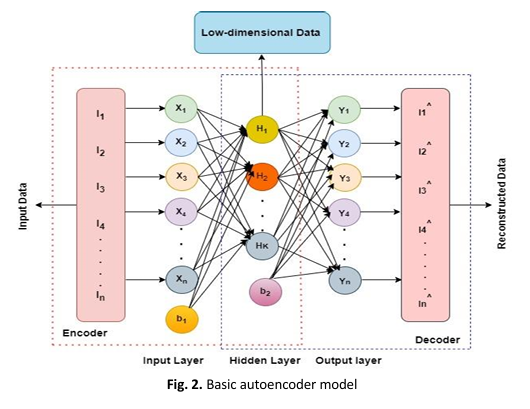
High-dimensional sparse numerical data are normally encountered in machine learning, recommender systems, finance and medical imaging. The problem with this type of data is that it has high dimensions (many features) and highly sparse (most values are zero), which is prone to overfitting. The data visualization can be achieved through a neural network architecture called stacked autoencoders. These multilayer autoencoders are designed to reconstruct input data, but overfitting is a major problem. To overcome this problem novel L1 Regularization-dropout technique is introduced to reduce overfitting and boost stacked autoencoder performance. L1 regularization penalizes large weights, simplifying data representations whereas the dropout technique randomly turns off neurons during training and makes the model dependent only on the selected turn-on neurons. The model employs batch normalization to improve the performance of the autoencoder. The approach was implemented on a high-dimensional sparse numerical dataset in the field of cybersecurity to minimize the loss function, measured by Mean Square Error (MSE) and Mean Absolute Error (MAE). The findings were compared to the conventional stacked autoencoder. The study revealed that the suggested method effectively mitigated the issue of overfitting. Stacked autoencoders, when combined with L1 regularisation and the dropout approach, are very successful in handling high-dimensional sparse numerical data in a diverse range of applications.
Downloads
Downloads
Published
How to Cite
Issue
Section






















