MFCC-GMM Method for Speaker Identification by Voice
DOI:
https://doi.org/10.37934/ard.128.1.163171Keywords:
MFCC, VQ, GMM, hamming, Fourier transform, mel-filter, code wordAbstract
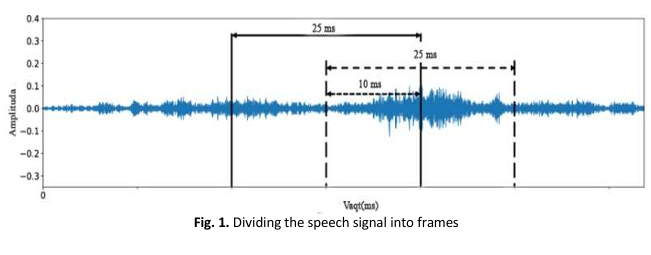
Voice, as a characteristic of humans, provides great opportunities for communication and identification. Today, voice recognition systems are widely used in many areas of human activity. However, the problem of developing perfect voice recognition systems is still considered an urgent task by researchers. Especially when the speech sample duration is relatively short, it is important to solve the problem of low recognition accuracy. Therefore, in this article, the Mel-frequency cepstral coefficients (MFCC) feature set extraction algorithm and Gaussian mixture model (GMM) were researched in the implementation of identification, based on which experimental researches were conducted on the recognition of a person based on his voice. In this, the speech samples of male and female speakers recorded in different environments were used and the efficiency of the methods was compared by applying the MFCC-GMM and MFCC-VQ methods to them. As a result, the MFCC-GMM method is found to be more accurate than the MFCC-VQ method. That is, in the text-dependent condition, the accuracy of the speech recognition ranged from 82.8% to 94.5% and in the text-independent condition, it showed an accuracy of 79.5% to 87.4%.
Downloads
Downloads
Published
How to Cite
Issue
Section






















