Assessment of Time Series Model for Predicting Long-Interval Consecutive Missing Values in Air Quality Dataset
DOI:
https://doi.org/10.37934/ard.127.1.1631Keywords:
air pollutant dataset, missing data, imputation method, time series analysis, ARIMAAbstract
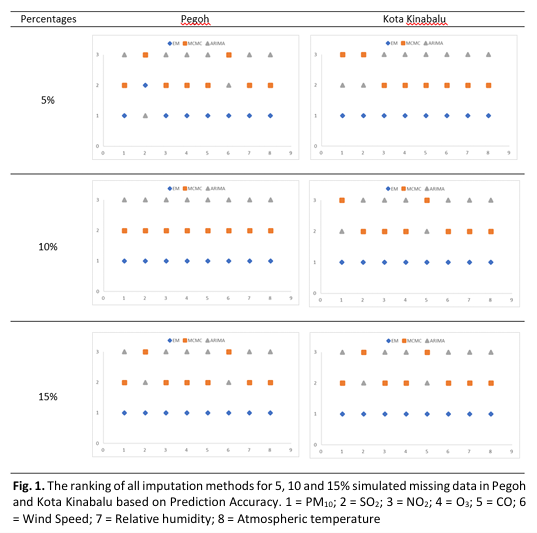
Air pollutant concentration in Malaysia is continuously monitored using the Continuous Ambient Air Quality Machine (CAAQM). During the observation phase by CAAQM, some air pollutant datasets were detected missing due to machine failure, maintenance, position changes and human error. Incomplete datasets especially with the longer gaps of consecutive missing observation may lead to several significant problems including loss of efficiency, difficulties in using some computational software and bias estimation due to differences of observed and predicted dataset. This study aim evaluates the performance of the time series method i.e. Auto Regression Integrated Moving Average (ARIMA) for filling long hours of missing data in an air pollution dataset. The dataset of PM10, SO2, NO2, O3, CO, wind speed, relative humidity and ambient temperature for Pegoh and Kota Kinabalu in 2018 were used for analysis. Monte Carlo Markov Chain (MCMC) and Expectation-Maximization (EM) were employed to compare with ARIMA's effectiveness in filling the simulated missing gaps in air quality dataset. Existing missing data in the raw data were pre-treated and then simulated into 5%, 10% and 15% of missing data ranging from 24-hour to 120-hour intervals. The performance of the imputation approach was assessed using Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Prediction Accuracy (PA) and Index of Agreement (IA). Overall, the Expectation-Maximization technique was selected the most effective at filling in simulated long gaps of missing data of air pollutant dataset with the range of IA from 0.74 to 0.77. In contrast, the ARIMA approach performed poorly in this research with range of IA value of 0.44 to 0.48. This was because of it requires past time-series data to generalize a forecast or impute missing data, hence, the forecast becomes a straight line and performed poorly at predicting series with long hours of missing observation.
Downloads
Downloads
Published
How to Cite
Issue
Section






















