Semi-Automatic Sentiment Identification for Malay-English Code-Switched Data
DOI:
https://doi.org/10.37934/ard.123.1.198212Keywords:
Sentiment analysis, code-switching, sentiment classification, natural language processingAbstract
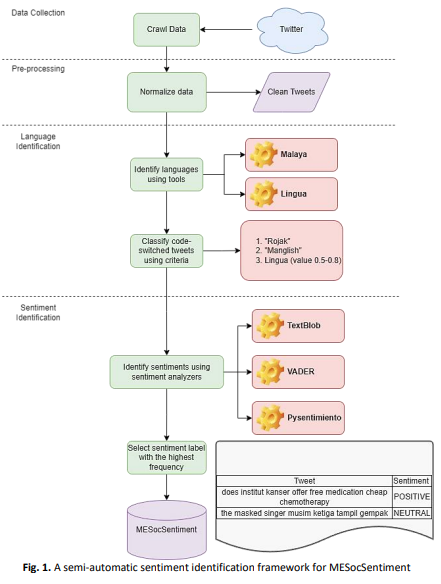
Informal online communication on social media platforms like Twitter, Facebook, and YouTube often involves code-switching between languages, notably Malay and English, in Malaysia due to its diverse society. This phenomenon challenges sentiment analysis tasks, as the intermixing of languages within sentences or phrases increases the likelihood of inaccurately classified sentiment. Sentiment analysers built with models trained with monolingual data will cause misclassification due to out-of-vocabulary issues, thus limiting the efficacy of these analysers on code-switched data. Plus, obtaining a code-switched corpus annotated with sentiment labels is scarce, and investigations on sentiment analysis on code-switched social media data are lacking, particularly on Malaysian social media posts. We proposed MESocSentiment, a Malay-English social media corpus with sentiment labels constructed via a semi-automatic sentiment identification method to address this challenge. The framework leveraged existing language identifiers and sentiment analysers to annotate code-switched data. We collected 229,566 tweets containing #Malaysia between August 12, 2022, and May 15, 2023. Using our strategy, we identified 19714 code-switched posts containing Malay and English words from the collection. Our analysis showed that 78.23% of the corpus had neutral sentiments, while 16.32% were positive and 5.44% negative. Furthermore, the descriptive analysis of tweet length revealed a range spanning 43 words, with a mean of 8.92 and a standard deviation of 5.56 words. This comprehensive framework contributes to a deeper understanding of sentiment expression within code-switched social media data, particularly in the context of Malaysia's linguistic and cultural diversity. Additionally, the MESocSentiment corpus is published on GitHub for future research.
Downloads
Downloads
Published
How to Cite
Issue
Section






















